部署NVIDIA MIG
备注
NVIDIA MIG(Multi-Instance GPU)部署 不需要独立的vGPU license
不过,如果要部署NVIDIA AI Enterprise,则因为包含了预构建的vGPU 驱动镜像,则需要使用NVIDIA License System(NLS)来配置(请参考 NVIDIA Docs Hub > Cloud Native Technologies > NVIDIA GPU Operator > NVIDIA AI Enterprise
NVIDIA AI Enterprise是一个云原生软件工具、库和框架的软件集,包括了NVIDIA NIM和NeMo微服务,用于加速和简化AI应用的开发、部署和伸缩。
部署要求
MIG功能是通过 NVIDIA GPU驱动 来提供的:
A100/A30 需要CUDA 11,
NVIDIA Driver版本525+H100及以后产品则需要CUDA 12
H100/H200
NVIDIA Driver版本450+B200
NVIDIA Driver版本570+Blackwell微内核则需要
NVIDIA Driver版本575+
操作系统
MIG只支持使用 NVIDIA CUDA 的 Linux 发行版
从
450.51.06版本以后废弃了/proc方式输出系统级接口, 建议使用/dev系统级接口通过 Kernel Cgroup 来控制访问MIG设备
支持配置选项如下:
裸金属硬件,包括容器环境
在支持的 hypervisor上管理GPU Pass-Through 到Linux guest操作系统
在支持的 hypervisor上实现 NVIDIA Virtual GPU (vGPU)
在A100/A30上设置MIG模式需要reset GPU: 一旦GPU进入MIG模式,实例管理就是动态的,并且设置是基于每一个GPU来进行的
在NVIDIA Ampere架构GPU,MIG模式在重启后保持不变,直到用户明确切换设置
在激活MIG之前,所有使用驱动模块的服务都必须停止
健康度监控服务
nvsmGPU健康监控
类似 DCGM-Exporter 的遥测服务
激活MIG模式需要
CAP_SYS_ADMIN能力,其他MIG管理,例如创建和销毁实例,则需要超级用户权限,不过可以通过/proc/中修改MIG的修订权限赋予普通用户这个权限。
MIG设备命名
默认情况下,一个MIG设备由一个"GPU 实例"和一个"计算实例"组成:

MIG 设备命名
正如 NVIDIA Multi-Instance GPU(MIG) 架构 所述,先划分GPU Instance(包含memory slice),然后再划分Compute Instance: Compute Instance会共享父级GPU Instance的GPU SM Slice和Memory Slice:
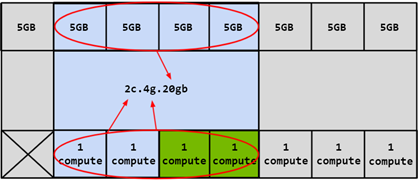
基于 4g.20gb 的GPU Instance再划分为Compute Instance,这里是 2c.4g.20gb
CUDA设备
单个 CUDA 进程都只能枚举一个 MIG 设备
CUDA 应用程序将 CI 及其父 GI 视为单个 CUDA 设备
CUDA 只能使用单个 CI,如果有多个可见的 CI,它将选择第一个可用的 CI
备注
上述MIG限制可能会再未来NVIDIA驱动中放宽
使用以下命令检查MIG设备:
nvidia-smi -L
MIG Profiles
不同的NVIDIA GPU对MIG profile支持不同,请参考 MIG User Guide: Supported MIG Profiles
MIG配置
核对 MIG配置环境要求
必须是NVIDIA
Ampere架构或更新的架构安装符合要求的CUDA和驱动版本(建议用最新版本)
如果使用 Docker 或 Kubernetes ,则需要安装
NVIDIA Container Toolkit (nvidia-docker2): v2.5.0 or later ( 为Docker安装NVIDIA Container Toolkit / 为containerd安装NVIDIA Container Toolkit )
NVIDIA K8s Device Plugin: v0.7.0 or later
NVIDIA gpu-feature-discovery: v0.2.0 or later
MIG可以通过以下两种方式进行编程管理:
使用NVIDIA Management Library (NVML) APIs(可以通过查看CUDA Toolkit软件包提供的NVML header
nvml.h了解MIG Management APIs)使用 nvidia-smi 命令行接口(可以通过
nvidia-smi mig --help查看支持选项)
对于RTX PRO 6000 Blackwell 和 RTX PRO 5000 Blackwell GPU,还需要关注 Additional Prerequisites for RTX PRO Blackwell GPUs 对 vBIOS 版本的要求。
激活MIG模式
默认情况下GPU 没有激活 MIG Mode
使用 nvidia-smi 命令可以检查MIG Mode
nvidia-smi 指定设备0nvidia-smi -i 0
输出案例:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB Off | 00000000:36:00.0 Off | 0 |
| N/A 29C P0 62W / 400W | 0MiB / 40537MiB | 6% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
激活MIG模式:
# nvidia-smi -i <GPU IDs> -mig 1
sudo nvidia-smi -i 0 -mig 1
可以使用不同的方式来引用GPU:
使用GPU indexes
PCI总线ID
UUID
如果没有指定GPU ID,则会激活系统上所有GPU的MIG Mode
MIG模式保持
警告
Hopper+ 架构以上的GPU重启系统会丢失MIG模式状态
早期的 Ampere 架构 GPU 由于GPU InforROM存储了一个状态位,所以重启系统MIG模式保持不变
当GPU启用MIG之后,根据GPU产品不同,可能需要重置GPU以使MIG模式生效:
Hopper+ 架构以上的GPU不再需要GPU Reset就能够生效MIG(所以驱动程序不会在后台重置GPU)
MIG 模式(禁用或启用状态) 仅在内核模块已加载情况下才会持续存在 : 如果操作系统重启则MIG模式不再续存(GPU InfoROM 中不再存储状态位)
卸载并重新加载驱动程序内核模块 也将禁用MIG模式
Ampere 架构 GPU,启动MIG模式后,驱动程序将尝试reset GPU以使MIG模式生效
Ampere 架构 GPU 在操作系统重启后会依然保留之前的MIG 模式(禁用或启用状态),这是因为GPU InfoROM 中存储了一个状态位
必须明确禁用 MIG 模式才能将 GPU 恢复到默认状态
驱动客户端
如果系统中有agent(如监控)在使用GPU,则可能不能执行GPU reset,此时会报错,例如:
$ sudo nvidia-smi -i 0 -mig 1
Warning: MIG mode is in pending enable state for GPU 00000000:07:00.0:In use by another client
00000000:07:00.0 is currently being used by one or more other processes (e.g. CUDA application or a monitoring application such as another instance of nvidia-smi). Please first kill all processes using the device and retry the command or reboot the system to make MIG mode effective.
All done.
此时可能需要停止 nvsm 和 dcgm 服务:
$ sudo systemctl stop nvsm
$ sudo systemctl stop dcgm
$ sudo nvidia-smi -i 0 -mig 1
Enabled MIG Mode for GPU 00000000:07:00.0
All done.
列出GPU Instance Profiles
NVIDIA驱动程序提供了配置文件(profiles)列表,来方便用户配置MIG功能时选择使用
列出支持的GPU Instance Profiles:
nvidia-smi mig -lgip
注意这里的参数 -lgip 表示 List GPU Instances Profiles ,后面的案例对于已经创建好的GI,则去掉 p 仅使用 -lgi 表示 List GPU Instances
输出案例(A100),这里高亮的是后面案例将要使用的ID为9的profile:
+-----------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|=============================================================================|
| 0 MIG 1g.5gb 19 7/7 4.75 No 14 0 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.5gb+me 20 1/1 4.75 No 14 1 0 |
| 1 1 1 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.10gb 15 4/4 9.62 No 14 1 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 3/3 9.62 No 28 1 0 |
| 2 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 2/2 19.50 No 42 2 0 |
| 3 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 1/1 19.50 No 56 2 0 |
| 4 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 1/1 39.25 No 98 5 0 |
| 7 1 1 |
+-----------------------------------------------------------------------------+
创建GPU Instance
使用
-cgi参数来创建GPU Instance,参数值可以是:Profile ID (e.g. 9, 14, 5)
使用profile的短名(例如
3g.20gb)使用GPU Instance的完成profile名字(例如
MIG 3g.20gb)
一旦GPU Instance创建完成后,就需要创建相应的 Compute Instance (CI),则使用 -C 参数
备注
如果不创建GPU Instance以及相应的Compute Instance,CUDA工作负载就无法在GPU上运行(仅仅激活MIG模式是不够的)
已创建的 MIG 设备在系统重启后不会保留
管理员需要重新创建MIG配置
可以使用NVIDIA MIG Partition Editor(或
mig-parted)工具创建在系统启动时重建MIG Geometry的 Systemd进程管理器 服务
以下案例创建了 2个
GPU Instances(注意,一个使用了profile ID9,另一个使用了3g.20gbprofile short name,实际上是一样的,所以其实是两个一样的GPU Instances,profiles之间使用逗号分隔),以及对应的Compute Instances:
GPU Instances 以及对应 Compute Instancessudo nvidia-smi mig -cgi 9,3g.20gb -C
输出类似:
GPU Instances 以及对应 Compute InstancesSuccessfully created GPU instance ID 2 on GPU 0 using profile MIG 3g.20gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 2 using profile MIG 3g.20gb (ID 2)
Successfully created GPU instance ID 1 on GPU 0 using profile MIG 3g.20gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 1 using profile MIG 3g.20gb (ID 2)
现在就可以查看 GPU Instances:
sudo nvidia-smi mig -lgi
输出类似:
+----------------------------------------------------+
| GPU instances: |
| GPU Name Profile Instance Placement |
| ID ID Start:Size |
|====================================================|
| 0 MIG 3g.20gb 9 1 4:4 |
+----------------------------------------------------+
| 0 MIG 3g.20gb 9 2 0:4 |
+----------------------------------------------------+
此时可以用不带任何参数的 nvidia-smi 查看GIs和相应的CIs:
nvidia-smi 输出显示GIs和相应的CIs+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 11MiB / 20224MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
| 0 2 0 1 | 11MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
其他的一些创建GI案例(混合了不同的profiles)
sudo nvidia-smi mig -cgi 19,14,5
sudo nvidia-smi mig -cgi 19,19,14,9
sudo nvidia-smi mig -cgi 9,19,14,19
Compute Instances
在创建了GPU Instances之后(如果没有同时使用 -C 创建相应的Compute Instances),就可以先查看 gi 对应的 ci profile,然后选择其中之一进行Compute Instances创建
查看CI profiles:
GI 所支持的 CI profilessudo nvidia-smi mig -lcip -gi 1
这里参数 -lcip 表示 List Compute Instance Profiles ,参数 -gi 表示 GPU Instances
GI 所支持的 CI profiles输出案例+--------------------------------------------------------------------------------------+
| Compute instance profiles: |
| GPU GPU Name Profile Instances Exclusive Shared |
| Instance ID Free/Total SM DEC ENC OFA |
| ID CE JPEG |
|======================================================================================|
| 0 1 MIG 1c.3g.20gb 0 0/3 14 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
| 0 1 MIG 2c.3g.20gb 1 0/1 28 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
| 0 1 MIG 3g.20gb 2* 0/1 42 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
创建3个
CI,这里使用了刚才输出中高亮的profile 0:
GI 1 上创建 compute instancesudo nvidia-smi mig -cci 0,0,0 -gi 1
这里参数 -cci 表示 Create Compute Instance , 参数 -gi 表示 GPU Instance
输出显示
GI 1 上创建 compute instanceSuccessfully created compute instance on GPU 0 GPU instance ID 1 using profile MIG 1c.3g.20gb (ID 0)
Successfully created compute instance on GPU 0 GPU instance ID 1 using profile MIG 1c.3g.20gb (ID 0)
Successfully created compute instance on GPU 0 GPU instance ID 1 using profile MIG 1c.3g.20gb (ID 0)
此时使用 nvidia-smi 检查( list ) Compute Instance :
Compute Instancessudo nvidia-smi mig -lci -gi 1
这里参数 -lci 表示 List Compute Instance
输出显示
Compute Instances+-------------------------------------------------------+
| Compute instances: |
| GPU GPU Name Profile Instance |
| Instance ID ID |
| ID |
|=======================================================|
| 0 1 MIG 1c.3g.20gb 0 0 |
+-------------------------------------------------------+
| 0 1 MIG 1c.3g.20gb 0 1 |
+-------------------------------------------------------+
| 0 1 MIG 1c.3g.20gb 0 2 |
+-------------------------------------------------------+
执行不带参数的
nvidia-smi显示当前GI和CI情况:
GI 和 CI+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 11MiB / 20224MiB | 14 0 | 3 0 2 0 0 |
+------------------+ +-----------+-----------------------+
| 0 1 1 1 | | 14 0 | 3 0 2 0 0 |
+------------------+ +-----------+-----------------------+
| 0 1 2 2 | | 14 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
销毁GPU Intances
一旦GPU进入了MIG模式,就可以动态配置 GI 和 CI ,也可以动态被销毁 destroy :
没有指定
CI和GI则destroy会销毁主机上所有CI和GI(注意销毁顺序和创建顺序相反,必须先销毁CI再销毁GI:
CI 和 GIsudo nvidia-smi mig -dci && sudo nvidia-smi mig -dgi
这里参数 -dci 表示 Destroy Compute Instance , -dgi 表示 Destroy GPU Instance
也可以指定
GI和CI进行销毁,这销毁GI1 上的CI0,1,2
CI 和 GIsudo nvidia-smi mig -dci -ci 0,1,2 -gi 1
监控MIG设备
对于监控MIG设备,包括GPU metrics特性(利用率和其他采样metrics),建议使用 NVIDIA DCGM (Data Center GPU Manager) v3 或更高版本
使用CUDA MPS
CUDA多进程服务(Multi-Process Service, MPS)支持在GPU上并发处理协作式多进程CUDA应用程序。MPS和MIG可以协同工作,从而有可能在某些工作负载下实现更高的利用率。
详细参考 architecture and provisioning sequence for MPS
在容器中运行CUDA应用
NVIDIA Container Toolkit 是现在 Docker GPU设备 的标准方法(早期的 Docker运行NVIDIA容器 已经停止开发),并且支持MIG设备,允许用户使用 容器运行时(Container Runtimes) 来运行GPU容器
备注
在Kubernetes中使用MIG设备
从 NVIDIA device plugin for Kubernetes v0.7.0开始,支持 在Kubernetes中使用NVIDIA MIG
备注
MIG设备节点和能力
当前,NVIDIA内核驱动将自己的接口通过一系列系统级别设备节点输出。每个物理GPU都有自己的设备节点,例如 nvidia0 , nvidia1 等
系统级接口
有两种不同的系统级接口,通过 nvidia-capabilities 工作:
/dev基于 Kernel Cgroup 的设备文件,也提供了第二层访问控制,不过主要控制机制是cgroups/proc基于用户权限和挂在的命名空间,有限度地提供部分能力
建议使用 /dev ,因为后续 /proc 将被废弃
在 nvidia.ko 内核模块加载参数 nv_cap_enable_devfs 设置为 0 时候,就会激活 /proc ;如果设置为 1 ,则激活 /dev