在FreeBSD Linux Jail中运行NVIDIA Cuda
我一直在想如何能够实现一个 FreeBSD机器学习 环境,结合FreeBSD强大的 ZFS 以及坚如磐石的基础,实现通常在Linux环境下的Machine Learning。
我最初想到的是 bhyve PCI Passthrough ,毕竟这是非常直觉的想法,通过PCIe Passthrough实现GPU直通给Linux虚拟机,这样就避免了 NVIDIA GPU 无法很好在FreeBSD支持的问题(我相像中厂商对FreeBSD硬件驱动支持都比较弱)。不过,现实总是比较残酷,在反复折腾 在bhyve中实现NVIDIA GPU passthrough 遇到各种问题,让人非常沮丧: 花费了大量的时间精力,这些时间本应该投入到现今火热一日千里的 LLM 大型语言模型 实践中。
linux jail思路
Davinci Resolve installed in Freebsd Jail 提供了一个新的思路:
在FreeBSD上安装
nvidia-driver linux-nvidia-libs libc6-shim libvdpau-va-gl libva-nvidia-driver(实际上和下文linuxulator思路是一致的)配置 FreeBSD Linux Jail 在Jail中运行 Ubuntu Linux
在Ubuntu Linux Jail中运行安装
nvidia-driver(这里思路有点乱,我不太确定Linux Jail中是否还要安装driver,因为FreeBSD Host上已经安装过driver了) 和nvidia-cuda-toolkit接下来就可以安装任意依赖NVIDIA CUDA的应用
备注
另一种解决思路是 在 FreeBSD Linuxulator 中运行NVIDIA Cuda ,更为简便
Host安装 Linuxulator 软件栈
NVIDIA为FreeBSD提供了原生的 nvidia-driver 驱动,所以方案类似 Docker运行NVIDIA容器 ,首先在FreeBSD Host中安装 nvidia-driver 以及支持 Linuxulator 运行模拟Linux驱动的 linux-nvidia-libs 库文件(我理解是将Linux层调用Linux版本 nvidia-driver 的API转换成调用FreeBSD版本 nvidia-driver )。此外,附加安装 libc6-shim 能够获得一个 nv-sglrun 工具来包装使用CUDA:
nvidia-driver (原生) 和 CUDA (Linux版)pkg install nvidia-driver linux-nvidia-libs libc6-shim
备注
DaVinci Resolve Freebsd 中另外安装的两个库文件:
libvdpau-va-gl: Linux二进制程序,提供应用程序使用VDPAU(Video Decode and Presentation API)来实现硬件功能,将 VDPAU 调用转换成视屏加速API(VA-API, Video Acceleration API),使用OpenGL来绘制和伸缩。这个库对于Intel GPU也有部分作用,因为Intel GPU没有实现原生VDPAU但支持VA-APIlibva-nvidia-driver: Linux平台的NVIDIA GPU作为转换层提供硬件视频解码的软件包,桥接了 VA-API (Video Acceleration API),被很多应用程序用于(NVIDIA)硬件解码。
上述两个库似乎是视频相关,我暂时没有安装
重启系统后执行
nvidia-smi发现报错:
nvidia-smi 显示没有驱动NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
手工加载 NVIDIA 驱动:
kldload nvidia
此时检查 kldstat | grep nvidia 看到有一个内核模块加载:
kldstat 输出中有 nvidiakldstat | grep nvidia
另外,还需要配置系统启动时自动加载 nvidia-devier ,设置 /boot/loader.conf :
/boot/loader.conf# NVIDIA
nvidia_load="YES"
警告
我遇到一个非常奇怪的问题,在 /boot/loader.conf 添加了 nvidia_load="YES" ,但是重启没有自动加载 nvidia 驱动,而是启动后每次都需要手工执行 kldload nvidia 加载。这让我很困惑,参考 Loading kernel modules automatically 似乎是配置文件有隐含特殊字符导致的,但是我没有找到解决方法。
输出显示:
kldstat 输出中有 nvidia22 1 0xffffffff83800000 604e158 nvidia.ko
但是很不幸,发现 nvidia-smi 报错依旧:
nvidia-smi 显示没有驱动NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
检查系统日志
dmesg显示:
dmesg 显示分配BAR错误nvidia0: <Unknown> on vgapci0
vgapci0: child nvidia0 requested pci_enable_io
vgapci0: 0x800000000 bytes of rid 0x14 res 3 failed (0, 0xffffffffffffffff).
nvidia0: NVRM: NVIDIA MEM resource alloc failed, BAR1 @ 0x14.
nvidia0: NVRM: NVIDIA hardware alloc failed.
device_attach: nvidia0 attach returned 6
这说明系统没有设置 Above 4G Decoding BIOS设置 或者说类似 HP DL360 Gen9 Large Bar Memory(Tesla P10) (相同概念的不同术语),需要调整BIOS
BIOS设置 Above 4G Decoding BIOS设置
在 Above 4G Decoding BIOS设置 针对我的 纳斯NASSE C246 ITX主板 需要配置2个BIOS位置:
Above 4G Decoding
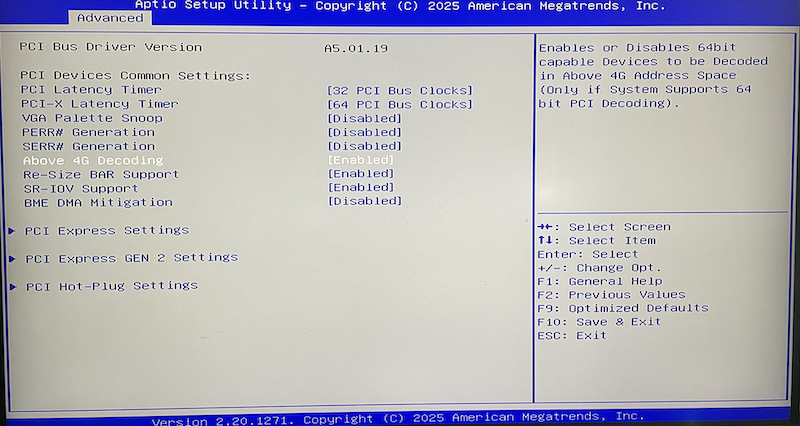
above 4GB mmio BIOS Assignment
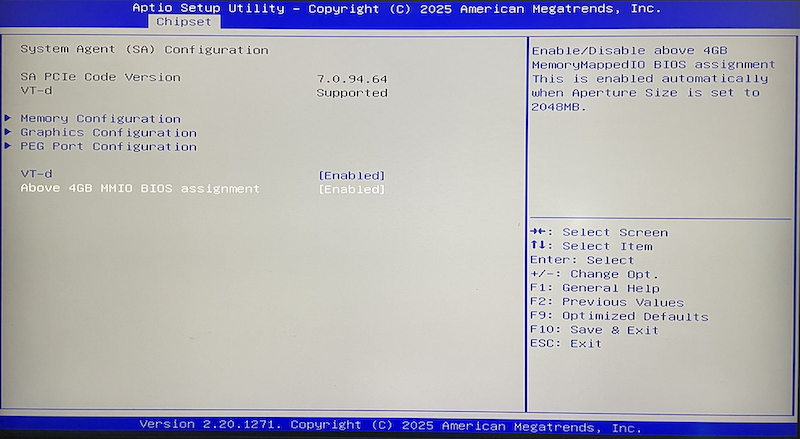
完成后重启主机,然后在FreeBSD Host主机上执行 nvidia-smi 此时就看到正常的输出信息(表明 Nvidia Tesla P10 GPU运算卡 已经工作正常:
nvidia-smi 输出显示GPU工作正常Fri Sep 26 19:51:25 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.82.07 Driver Version: 580.82.07 CUDA Version: N/A |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA Graphics Device Off | 00000000:01:00.0 Off | 0 |
| N/A 32C P0 36W / 150W | 0MiB / 23040MiB | 2% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
注意,这里输出信息中仅显示 Driver Version: 580.82.07 ,而CUDA版本是空白的 CUDA Version: N/A 。这时因为当前使用的 nvidia-smi 仅仅是FreeBSD原生的 nvidia-driver
通过
nv-sglrun运行nvidia-smi则是执行Linux程序(通过 Linuxulator ),会通过CUDA,此时会看到CUDA版本信息:
nv-sglrun 运行 nvidia-sminv-sglrun nvidia-smi
输出信息:
nv-sglrun 运行 nvidia-smi 输出信息中有CUDA版本信息/usr/local/lib/libc6-shim/libc6.so: shim init
/usr/local/lib/libc6-shim/libc6.so: unable to load libinotify.so.0 (Shared object "libinotify.so.0" not found, required by "nvidia-smi")
Fri Sep 26 19:53:59 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.82.07 Driver Version: 580.82.07 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA Graphics Device Off | 00000000:01:00.0 Off | 0 |
| N/A 33C P0 36W / 150W | 0MiB / 23040MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
至此,FreeBSD nvidia-driver 以及通过 Linuxulator 运行 CUDA 已部署完毕,接下来就可以进行 Machine Learning 工作。当然,为了进一步方便工作,还可以继续部署 FreeBSD Linux Jail 来实现隔离且完整的机器学习环境
如果要直接在FreeBSD Linuxulator 环境运行Linux版本Conda,可以安装
minicondaLinux版本:
pkg install linux-miniconda-installer
miniconda-installer
此时会安装一个Linux版本的 miniconda,可以用于今后机器学习安装对应的软件包
Linux Jail实现CUDA实践
已经完成了上述Host主机上安装
nvidia-driver等软件堆栈
备注
由于上文已经在FreeBSD Host中安装了 nvidia-driver ,所以参考 Docker运行NVIDIA容器 架构,在Jail中,应该只需要安装Linux版本的 CUDA Toolkit,而不需要安装完整版本的CUDA(包含 cuda-toolkit 和 nvidia-driver )
从NVIDIA官方提供 NVIDIA CUDA Toolkit repo 下载 选择
linux=>x86_64=>Ubuntu=>24.04=>deb(network)
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
安装
nvidia-cuda-toolkit:
nvidia-cuda-toolkitapt-get install cuda-toolkit
备注
我发现NVIDIA提供了不同的CUDA Toolkit: 仓库中有
nvidia-cuda-toolkitcuda-toolkit
两者在 Ubuntu Linux core系统中安装:
nvidia-cuda-toolkit需要6037 MB空间
cuda-toolkit需要7474 MB空间两者安装的软件包和依赖有所不同
以下这段内容来自Google AI:
nvidia-cuda-toolkit是完整版本的CUDA Toolkit,也称为full development suite。包含了完整CUDA开发工具和库,适合需要完整toolchain来编译、调试和prifile CUDA程序的开发者。当安装完整版本nvidia-cuda-toolkit通常会处理依赖以及安装NVIDIA驱动( 这段似乎不正确 Google AI似乎搞混了Conda环境中的
cudatoolkit包)cuda-toolkit通常用于Conda包或者较为核心的toolkit,软件包较少仅包含运行软件(如 Tensorflow )所需的库,没有包含完整的开发toolchain。这个软件包组合通常是最终用户使用的,仅用于预编译应用程序或Python软件包,如 Pytorch 或 Tensorflow 。安装cuda-toolkit通常假设系统已经安装了NVIDIA GPU驱动,所以安装软件更少。如果需要完整开发环境来编写C++ CUDA程序,则安装完整版本
nvidia-cuda-toolkit; 如果只是最终用户运行预编译程序,例如安装运行 深度学习 框架如 Pytorch 或 Tensorflow ,则通常安装轻量级cuda-toolkit(通过conda或pip安装cudatoolkit软件包)
这里有一些报错,看来是安装 nvidia-cuda-toolkit 时自动安装和配置 Systemd进程管理器 导致的:
nvidia-cuda-toolkit 报错Setting up libsystemd-shared:amd64 (255.4-1ubuntu8.10) ...
Setting up systemd-dev (255.4-1ubuntu8.10) ...
Setting up systemd (255.4-1ubuntu8.10) ...
⚠️ /proc/ is not mounted. This is not a supported mode of operation. Please fix
your invocation environment to mount /proc/ and /sys/ properly. Proceeding anyway.
Your mileage may vary.
⚠️ /proc/ is not mounted. This is not a supported mode of operation. Please fix
your invocation environment to mount /proc/ and /sys/ properly. Proceeding anyway.
Your mileage may vary.
⚠️ /proc/ is not mounted. This is not a supported mode of operation. Please fix
your invocation environment to mount /proc/ and /sys/ properly. Proceeding anyway.
Your mileage may vary.
/proc/ is not mounted, but required for successful operation of systemd-tmpfiles. Please mount /proc/. Alternatively, consider using the --root= or --image= switches.
Failed to take /etc/passwd lock: Invalid argument
dpkg: error processing package systemd (--configure):
installed systemd package post-installation script subprocess returned error exit status 1
Errors were encountered while processing:
systemd
E: Sub-process /usr/bin/dpkg returned an error code (1)
备注
我曾经想是不是应该改为安装 NVIDIA Container Toolkit ?面向容器定制的toolkit或许可以避免 systemd 问题...
我参考 NVIDIA Container Toolkit 发现也不行,这个 NVIDIA Container Toolkit 是一个复杂的安装在Host上的软件包,用于配置 Docker 或其他 Container 运行时来实现容器化运行 CUDA Toolkit 。
也就是说,确实应该在容器(或者Jail)内部安装 CUDA Toolkit ,但是没法使用NVIDIA官方的 NVIDIA Container Toolkit ,这个软件包和Linux平台深度绑定,只是为了能够方便构建和运行容器,但无法在FreeBSD上使用。
这个问题似乎不好解决,但也可能可以解决(google ai给了启发):
Devuan 是一个 Debian fork版本,采用了
sysvinit系统替代 Systemd进程管理器 ,理论上当安装nvidia-cuda-toolkit的依赖时或许可以避免systemd问题(不过也取决于NVIDIA开发的软件包是否强制依赖了systemd)使用CUDA runfile installer安装,有可能通过
--override参数bypass掉依赖检查,不过CUDA系统可能会依赖才能工作
参考
Davinci Resolve installed in Freebsd Jail 油管上NapoleonWils0n围绕FreeBSD有不少视频编码解码的解析,其中关于FreeBSD Jail运行Ubuntu来实现NVIDIA CUDA 文档见 DaVinci Resolve Freebsd
PyTorch and Stable Diffusion on FreeBSD 思路相同,通过结合FreeBSD
nvidia-driver和 Linuxulator 运行Linux版本CUDA来实现一个机器学习环境