本地化部署DeepSeek-R1 CPU架构(LFS环境)
在 Debian 环境中初步验证了 本地化部署DeepSeek-R1 CPU架构 ,我将 HPE ProLiant DL380 Gen9服务器 物理主机上的Host操作系统切换到自己编译定制的 LFS(Linux from scratch) 系统,从源代码重新编译 在LFS中CPU架构LLaMA.cpp安装 ,然后执行本地部署 DeepSeek-R1 CPU架构(LFS环境)。
安装llama.cpp
我在 CPU架构LLaMA.cpp安装 按照以下方式完成编译安装:
build 目录重新配置编译rm -rf llama.cpp/build
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DLLAMA_CURL=ON
cmake --build llama.cpp/build --config Release --clean-first -j 40
运行
./llama.cpp/build/bin/llama-server \
--model unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf \
--port 8081
交互
简单交互可以使用 curl :
curl -X POST "http://localhost:8081/completion" \
-H "Content-Type: application/json" \
-d '{"prompt": "编写bash脚本,检查字符串A是否包含在字符串B中,并给出脚本解释"}'
这次运行没有指定线程数量,观察运行时大约消耗了一半cpu数量: Load 大约 23 ,也就是一半的cpu core(超线程是48)
比较奇怪,未指定并发线程数量,看起来也只是用了一半的cpu能力,这个cpu分布是怎么实现的?我下次验证准备关闭超线程看看能否真如网上所说提高性能。
以下是运行推理时的cpu运行情况:
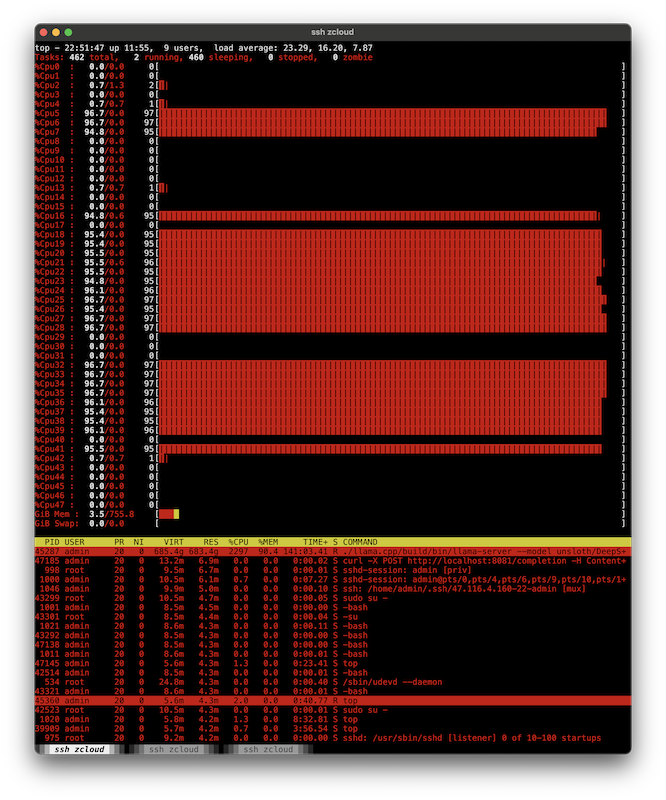
由于分布cpu负载随机,看起来确实会导致在同一个cpu core的两个超线程分发负载,这样会有资源竞争,可能降低效率。后续验证准备关闭超线程。
奔溃,运行了快2个小时,最后报错了
{"error":{"code":500,"message":"context shift is disabled","type":"server_error"}}
slot launch_slot_: id 0 | task 3 | processing task
slot update_slots: id 0 | task 3 | new prompt, n_ctx_slot = 4096, n_keep = 0, n_prompt_tokens = 19
slot update_slots: id 0 | task 3 | need to evaluate at least 1 token to generate logits, n_past = 19, n_prompt_tokens = 19
slot update_slots: id 0 | task 3 | kv cache rm [18, end)
slot update_slots: id 0 | task 3 | prompt processing progress, n_past = 19, n_tokens = 1, progress = 0.052632
slot update_slots: id 0 | task 3 | prompt done, n_past = 19, n_tokens = 1
slot release: id 0 | task 3 | stop processing: n_past = 4095, truncated = 0
srv send_error: task id = 3, error: context shift is disabled
srv update_slots: no tokens to decode
srv update_slots: all slots are idle
srv cancel_tasks: cancel task, id_task = 3
srv update_slots: all slots are idle
srv log_server_r: request: POST /completion 127.0.0.1 500
仔细检查服务器端llama_server启动信息:
build: 4750 (0b3863ff) with cc (GCC) 14.2.0 for x86_64-pc-linux-gnu
system info: n_threads = 24, n_threads_batch = 24, total_threads = 48
system_info: n_threads = 24 (n_threads_batch = 24) / 48 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | F
MA = 1 | LLAMAFILE = 1 | OPENMP = 1 | AARCH64_REPACK = 1 |
main: HTTP server is listening, hostname: 127.0.0.1, port: 8081, http threads: 47
main: loading model
srv load_model: loading model 'unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf'
llama_model_loader: additional 14 GGUFs metadata loaded.
llama_model_loader: loaded meta data with 48 key-value pairs and 1025 tensors from unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-
Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = deepseek2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = DeepSeek R1 BF16
llama_model_loader: - kv 3: general.quantized_by str = Unsloth
llama_model_loader: - kv 4: general.size_label str = 256x20B
llama_model_loader: - kv 5: general.repo_url str = https://huggingface.co/unslo
th
llama_model_loader: - kv 6: deepseek2.block_count u32 = 61
llama_model_loader: - kv 7: deepseek2.context_length u32 = 163840
llama_model_loader: - kv 8: deepseek2.embedding_length u32 = 7168
llama_model_loader: - kv 9: deepseek2.feed_forward_length u32 = 18432
llama_model_loader: - kv 10: deepseek2.attention.head_count u32 = 128
llama_model_loader: - kv 11: deepseek2.attention.head_count_kv u32 = 128
llama_model_loader: - kv 12: deepseek2.rope.freq_base f32 = 10000.000000
llama_model_loader: - kv 13: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 14: deepseek2.expert_used_count u32 = 8
llama_model_loader: - kv 15: general.file_type u32 = 7
llama_model_loader: - kv 16: deepseek2.leading_dense_block_count u32 = 3
llama_model_loader: - kv 17: deepseek2.vocab_size u32 = 129280
llama_model_loader: - kv 18: deepseek2.attention.q_lora_rank u32 = 1536
llama_model_loader: - kv 19: deepseek2.attention.kv_lora_rank u32 = 512
llama_model_loader: - kv 20: deepseek2.attention.key_length u32 = 192
llama_model_loader: - kv 21: deepseek2.attention.value_length u32 = 128
llama_model_loader: - kv 22: deepseek2.expert_feed_forward_length u32 = 2048
llama_model_loader: - kv 23: deepseek2.expert_count u32 = 256
llama_model_loader: - kv 24: deepseek2.expert_shared_count u32 = 1
llama_model_loader: - kv 25: deepseek2.expert_weights_scale f32 = 2.500000
llama_model_loader: - kv 26: deepseek2.expert_weights_norm bool = true
llama_model_loader: - kv 27: deepseek2.expert_gating_func u32 = 2
llama_model_loader: - kv 28: deepseek2.rope.dimension_count u32 = 64
llama_model_loader: - kv 29: deepseek2.rope.scaling.type str = yarn
llama_model_loader: - kv 30: deepseek2.rope.scaling.factor f32 = 40.000000
llama_model_loader: - kv 31: deepseek2.rope.scaling.original_context_length u32 = 4096
llama_model_loader: - kv 32: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000
llama_model_loader: - kv 33: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 34: tokenizer.ggml.pre str = deepseek-v3
llama_model_loader: - kv 35: tokenizer.ggml.tokens arr[str,129280] = ["<__begin_of_sentence__>",
"<...
llama_model_loader: - kv 36: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1,
1, 1, 1, ...
llama_model_loader: - kv 37: tokenizer.ggml.merges arr[str,127741] = ["_ t", "_ a", "i n", "_ _",
"h e...
llama_model_loader: - kv 38: tokenizer.ggml.bos_token_id u32 = 0
llama_model_loader: - kv 39: tokenizer.ggml.eos_token_id u32 = 1
llama_model_loader: - kv 40: tokenizer.ggml.padding_token_id u32 = 128815
llama_model_loader: - kv 41: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 42: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 43: tokenizer.chat_template str = {% if not add_generation_pro
mpt is de...
llama_model_loader: - kv 44: general.quantization_version u32 = 2
llama_model_loader: - kv 45: split.no u16 = 0
llama_model_loader: - kv 46: split.count u16 = 15
llama_model_loader: - kv 47: split.tensors.count i32 = 1025
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 664 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = Q8_0
print_info: file size = 664.29 GiB (8.50 BPW)
load: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
load: special tokens cache size = 819
load: token to piece cache size = 0.8223 MB
print_info: arch = deepseek2
print_info: vocab_only = 0
print_info: n_ctx_train = 163840
print_info: n_embd = 7168
print_info: n_layer = 61
print_info: n_head = 128
print_info: n_head_kv = 128
print_info: n_rot = 64
print_info: n_swa = 0
print_info: n_embd_head_k = 192
print_info: n_embd_head_v = 128
print_info: n_gqa = 1
print_info: n_embd_k_gqa = 24576
print_info: n_embd_v_gqa = 16384
print_info: f_norm_eps = 0.0e+00
print_info: f_norm_rms_eps = 1.0e-06
print_info: f_clamp_kqv = 0.0e+00
print_info: f_max_alibi_bias = 0.0e+00
print_info: f_logit_scale = 0.0e+00
print_info: n_ff = 18432
print_info: n_expert = 256
print_info: n_expert_used = 8
print_info: causal attn = 1
print_info: pooling type = 0
print_info: rope type = 0
print_info: rope scaling = yarn
print_info: freq_base_train = 10000.0
print_info: freq_scale_train = 0.025
print_info: n_ctx_orig_yarn = 4096
print_info: rope_finetuned = unknown
print_info: ssm_d_conv = 0
print_info: ssm_d_inner = 0
print_info: ssm_d_state = 0
print_info: ssm_dt_rank = 0
print_info: ssm_dt_b_c_rms = 0
print_info: model type = 671B
print_info: model params = 671.03 B
print_info: general.name = DeepSeek R1 BF16
print_info: n_layer_dense_lead = 3
print_info: n_lora_q = 1536
print_info: n_lora_kv = 512
print_info: n_ff_exp = 2048
print_info: n_expert_shared = 1
print_info: expert_weights_scale = 2.5
print_info: expert_weights_norm = 1
print_info: expert_gating_func = sigmoid
print_info: rope_yarn_log_mul = 0.1000
print_info: vocab type = BPE
print_info: n_vocab = 129280
print_info: n_merges = 127741
print_info: BOS token = 0 '<__begin_of_sentence__>'
print_info: EOS token = 1 '<__end_of_sentence__>'
print_info: EOT token = 1 '<__end_of_sentence__>'
print_info: PAD token = 128815 '<__PAD_TOKEN__>'
print_info: LF token = 201 '_' 22:42:39 [31/1815]
print_info: FIM PRE token = 128801 '<__fim_begin__>'
print_info: FIM SUF token = 128800 '<__fim_hole__>'
print_info: FIM MID token = 128802 '<__fim_end__>'
print_info: EOG token = 1 '<__end_of_sentence__>'
print_info: max token length = 256
load_tensors: loading model tensors, this can take a while... (mmap = true)
load_tensors: CPU_Mapped model buffer size = 45565.90 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 46661.11 MiB
load_tensors: CPU_Mapped model buffer size = 28077.60 MiB
....................................................................................................
llama_init_from_model: n_seq_max = 1
llama_init_from_model: n_ctx = 4096
llama_init_from_model: n_ctx_per_seq = 4096
llama_init_from_model: n_batch = 2048
llama_init_from_model: n_ubatch = 512
llama_init_from_model: flash_attn = 0
llama_init_from_model: freq_base = 10000.0
llama_init_from_model: freq_scale = 0.025
llama_init_from_model: n_ctx_per_seq (4096) < n_ctx_train (163840) -- the full capacity of the model will not be utilize
d
llama_kv_cache_init: kv_size = 4096, offload = 1, type_k = 'f16', type_v = 'f16', n_layer = 61, can_shift = 0
llama_kv_cache_init: CPU KV buffer size = 19520.00 MiB
llama_init_from_model: KV self size = 19520.00 MiB, K (f16): 11712.00 MiB, V (f16): 7808.00 MiB
llama_init_from_model: CPU output buffer size = 0.49 MiB
llama_init_from_model: CPU compute buffer size = 1186.01 MiB
llama_init_from_model: graph nodes = 5025
llama_init_from_model: graph splits = 1
common_init_from_params: KV cache shifting is not supported for this model, disabling KV cache shifting
common_init_from_params: setting dry_penalty_last_n to ctx_size = 4096
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
srv init: initializing slots, n_slots = 1
slot init: id 0 | task -1 | new slot n_ctx_slot = 4096
main: model loaded
main: chat template, chat_template: {% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}
{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='', is_first_sp=true
) %}{%- for message in messages %}{%- if message['role'] == 'system' %}{%- if ns.is_first_sp %}{% set ns.system_prompt =
ns.system_prompt + message['content'] %}{% set ns.is_first_sp = false %}{%- else %}{% set ns.system_prompt = ns.system_
prompt + '\n\n' + message['content'] %}{%- endif %}{%- endif %}{%- endfor %}{{ bos_token }}{{ ns.system_prompt }}{%- for
message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<__User__>' + message['conten
t']}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' in message %}{%- set ns.is_tool = false -%}{%- f
or tool in message['tool_calls'] %}{%- if not ns.is_first %}{%- if message['content'] is none %}{{'<__Assistant__><__too
l_calls_begin__><__tool_call_begin__>' + tool['type'] + '<__tool_sep__>' + tool['function']['name'] + '\n' + '```json' +
'\n' + tool['function']['arguments'] + '\n' + '```' + '<__tool_call_end__>'}}{%- else %}{{'<__Assistant__>' + message['
content'] + '<__tool_calls_begin__><__tool_call_begin__>' + tool['type'] + '<__tool_sep__>' + tool['function']['name'] +
'\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<__tool_call_end__>'}}{%- endif %}{%- set ns.
is_first = true -%}{%- else %}{{'\n' + '<__tool_call_begin__>' + tool['type'] + '<__tool_sep__>' + tool['function']['nam
e'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<__tool_call_end__>'}}{%- endif %}{%- en
dfor %}{{'<__tool_calls_end__><__end_of_sentence__>'}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls'
not in message %}{%- if ns.is_tool %}{{'<__tool_outputs_end__>' + message['content'] + '<__end_of_sentence__>'}}{%- set
ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = c
ontent.split('</think>')[-1] %}{% endif %}{{'<__Assistant__>' + content + '<__end_of_sentence__>'}}{%- endif %}{%- endif
%}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<__tool_outputs_begin
__><__tool_output_begin__>' + message['content'] + '<__tool_output_end__>'}}{%- set ns.is_output_first = false %}{%- els
e %}{{'<__tool_output_begin__>' + message['content'] + '<__tool_output_end__>'}}{%- endif %}{%- endif %}{%- endfor -%}{%
if ns.is_tool %}{{'<__tool_outputs_end__>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<__Assistant
__>'}}{% endif %}, example_format: 'You are a helpful assistant
<__User__>Hello<__Assistant__>Hi there<__end_of_sentence__><__User__>How are you?<__Assistant__>'
main: server is listening on http://127.0.0.1:8081 - starting the main loop
srv update_slots: all slots are idle
解决方法是加上运行参数 --cache-type-k q8_0
./llama.cpp/build/bin/llama-server \
--model unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf \
--cache-type-k q8_0 \
--port 8081
初步运行结果
得到DeepSeek的返回结果
?
好的,现在我要编写一个bash脚本,用来检查字符串A是否包含在字符串B中。我需要仔细思考怎么在bash中实现这个功能。首先,我得回忆一下bash中的字符串操作有哪些方法。比如,可以用通配符或者正则表达式来匹配吗?或者是使用grep命令?或者是利用字符串比较操作符?
假设字符串A和字符串B都是变量存储的。比如,定义两个变量:stringA和stringB。现在需要判断stringB里是否包含stringA的内容。
首先想到的是在bash中使用条件判断结构,比如[[ ... ]]这样的结构。记得在双括号里面可以使用一些模式匹配的功能,比如用==操作符加上通配符。例如,如果stringB包含stringA的话,那么[[ $stringB == "$stringA" ]]应该返回真。这里的*表示任意字符的前后匹配,所以整个表达式就是检查stringB是否包含stringA的任何位置。
不过需要注意的是,变量是否被正确引用。例如,这里stringB外面没有引号,而$stringA被双引号包裹起来。这样处理的话,可能在某些情况下会遇到问题吗?比如,如果stringA中有空格或者特殊字符的话,会不会导致问题?可能需要测试一下。
或者另一种方法是使用grep命令,通过管道将stringB传给它,然后检查是否匹配stringA的模式。例如,echo "$stringB" | grep -q "$stringA"。如果grep找到匹配项,返回状态码是0,否则非零。然后可以通过判断$?的值来确定是否存在匹配。不过这种方法可能需要更多的进程间调用,效率可能稍低,但对于简单的脚本来说应该没问题。
另外,还可以考虑使用bash的正则表达式匹配。比如,使用[[ $stringB =~ $stringA ]]这样的结构。这时候,如果stringA被当作正则表达式来解析的话,可能需要转义一些特殊字符。比如,如果stringA中有*或者.等字符,可能会导致正则表达式行为不符合预期。这种情况下,可能需要将stringA中的字符进行转义,或者直接使用固定的字符串模式。
那么,这三种方法中哪一种更可靠呢?
使用通配符的方式可能更简单直接,不需要考虑正则表达式的特殊字符问题,因为此时stringA会被当作普通字符串来处理,而前后的*表示匹配任何字符。比如,如果stringA是"abc",那么检查的是stringB中是否有连续的abc出现。而如果使用正则表达式的话,如果stringA中有特殊字符,比如点号或者星号,可能需要进行处理。所以在这种情况下,使用通配符的方式可能更安全。
因此,我的思路是采用第一种方法:在双括号中使用模式匹配来判断stringB是否包含stringA。即:
if [[ "$stringB" == *"$stringA"* ]]; then
echo "包含"
else
echo "不包含"
fi
这样写的话,需要注意变量替换是否被正确执行。例如,如果stringA包含空格或者特殊字符,是否会被正确解析。在双引号中的变量替换应该能正确处理这些情况,因为双引号允许变量扩展,同时保留字面值
除了
$、` 、\\ 和!
等特殊字符),所以这里应该没问题。
那现在,编写一个脚本,接受两个参数,分别是字符串A和字符串B,然后判断B是否包含A。
比如,脚本名称是check_substring.sh,执行时输入:
./check_substring.sh "abc" "defghabcxyz"
应该输出包含。
那么脚本的结构大致如下:
#!/bin/bash
# 获取输入参数
stringA="$1"
stringB="$2"
# 检查参数是否提供
if [[ -z "$stringA" || -z "$stringB" ]]; then
echo "错误:需要提供两个字符串参数。"
exit 1
fi
# 判断B是否包含A
if [[ "$stringB" == *"$stringA"* ]]; then
echo "字符串B包含字符串A。"
else
echo "字符串B不包含字符串A。"
fi
exit 0
现在需要测试这种情况是否正确。
比如,当字符串A含有空格的时候,比如stringA是"hello world",stringB是"there is a hello world here",这时在参数传递的时候是否正确?
当用户调用脚本时,输入两个参数,如果第二个参数本身包含空格,需要用引号括起来。例如:
./check_substring.sh "hello world" "this string has hello world inside"
这样的话,参数1是"hello world",参数2是"this string has hello world inside",脚本中变量赋值正确,条件判断也能正常工作。
另一个测试案例是当stringA为空的情况。这时候,脚本会报错,因为参数没有提供。比如,如果用户只输入了一个参数,那么第二个参数为空,脚本会提示错误,因为stringA或者stringB为空。这里脚本的开头检查了是否两个参数都不为空。也就是说,如果用户传递空字符串作为参数的话,比如:
./check_substring.sh "" "something"
这时候,stringA是空,-z检测会成立,触发错误信息。这是否正确?
根据需求,可能允许空字符串作为stringA。例如,如果stringA是空,那么应该任何字符串B都包含它吗?这可能是一个边界情况需要处理。比如,在编程中,空字符串是否是所有字符串的子串?
例如,在编程语言中,判断一个空字符串是否是另一个字符串的子串,通常返回是,因为空字符串可以看作存在于任何位置。比如,在Java中,s.contains("")总是返回true。但这个问题是否适用于当前脚本的需求?
这个问题需要根据实际需求来决定。如果脚本的用户期望当stringA为空时,视为存在,则现有的脚本会报错,这样可能不对。这时候,脚本的条件判断可能需要调整。例如,允许stringA为空,而如果用户没有传递足够的参数,才报错。
目前的脚本中,参数的处理是检查两个变量是否为空。但如果用户传递了空字符串作为参数,比如第一个参数为空,例如:./check_substring.sh "" "abc",这时候,脚本会因为第一个参数为空而报错。这可能与用户的预期不符。比如,用户可能希望检查空字符串是否包含在B中。
这里可能需要改进参数检查的逻辑。例如,正确的做法是检查是否提供了两个参数,而不是检查参数是否为空。因为用户可能确实想传递空字符串作为参数。
在bash中,$#变量代表参数的个数。所以正确的检查应该是,如果参数个数小于2,则报错。比如:
if [[ $# -ne 2 ]]; then
echo "错误:需要两个参数。"
exit 1
fi
这样,不管参数的内容是否为空,只要用户提供了两个参数,脚本都会继续执行。而如果用户只传递了一个参数,或者没有参数,就会报错。这样更合理,因为用户可能有意识地将空字符串作为参数传入。比如:
./check_substring.sh "" "test" # 检查空字符串是否存在于test中
在这种情况下,根据条件判断,此时stringA为空,stringB为"test"。这时候,在判断条件[[ "$stringB" == "$stringA" ]]的时候,因为stringA是空,模式就变成了*""*,即匹配任意字符串。所以不管stringB是什么,这个条件都是真,所以会输出“包含”。
这是否符合预期呢?
根据编程惯例,空字符串是任何字符串的子串。例如,在Python中,"" in "abc"返回True。所以在这种情况下,脚本的正确行为应该是当stringA为空时,输出包含。但根据当前的条件判断,确实如此。
所以修改后的参数检查应该是判断参数个数是否为2,而不是参数内容是否为空。
所以,调整后的脚本:
#!/bin/bash
# 检查参数个数是否为2
if [[ $# -ne 2 ]]; then
echo "错误:需要提供两个字符串参数。"
exit 1
fi
stringA="$1"
stringB="$2"
# 判断B是否包含A
if [[ "$stringB" == *"$stringA"* ]]; then
echo "字符串B包含字符串A。"
else
echo "字符串B不包含字符串A。"
fi
exit 0
这样,当用户传递空字符串作为参数时,脚本依然正确运行。例如:
输入:./check_substring.sh "" "anything",此时输出“包含”。
这符合预期。
另一个测试案例:当stringA的长度大于stringB时,例如,stringA是"abcdef",stringB是"abc"。此时,判断条件不成立,输出不包含。
测试其他情况,比如特殊字符。例如,stringA是"",stringB是"abcdef"。这时候,由于使用的是通配符匹配,这里的星号是否会被视为通配符?
此时,变量stringA的值是*,那么在模式匹配中,会被当作普通字符吗?比如,如果使用[[ "$stringB" == "$stringA" ]],这里的模式是字符串中包含*吗?
此时,变量stringA的值为*,所以模式展开后是*"",也就是任何字符,加上一个*,再加上任何字符,所以匹配的是包含的字符串。比如,当stringB是"abcdef"时,条件成立。
是的,这种处理是正确的。因为当使用双引号包裹变量时,变量中的内容会被当作字面值,而不会进行通配符扩展。例如:
stringA="*"
[[ "abc*def" == *"$stringA"* ]]
此时,变量替换后的结果是*"",此时bash在双括号中的模式匹配会处理这个模式,其中变量中的*会被当作普通字符吗?
或者可能被当作通配符?这时候可能需要测试。
假设stringA是星号,stringB是"abc*def"。那么是否判断为包含?
在测试时,假设执行:
stringA='*'
stringB='abc*def'
[[ $stringB == *"$stringA"* ]] && echo yes || echo no
输出应该是yes,因为这里的$stringA的值是*,所以在模式中变成*"",也就是在任意字符中间有一个号,而stringB确实有这个星号。所以此时结果为yes。这说明在双引号中的变量替换确实将作为普通字符处理,而通配符只有在不引用的时候才会被处理。
但可能这里有误解,因为当使用变量的时候,是否会被视为模式中的通配符?
或者,双引号包裹的变量展开是否被视为字面字符串?
例如,如果变量stringA的值是"a*",而stringB的值是"abc",那么模式匹配是否允许通配符?
比如:
stringA="a*"
stringB="abc"
[[ $stringB == *"$stringA"* ]]
这时候,模式变成*"a*"。这时候,变量替换后的结果是a*,这时候是否被视为通配符?或者由于双引号的存在,其中的星号被视为字面量?
此时,当变量被双引号包裹时,里面的特殊字符如会被当作字面量,而不是通配符。因此,模式匹配实际上会寻找字符串中的"a"。例如,在stringB是"axyz"的时候会匹配,但在stringB是"abc"时则不会匹配。因为双引号中的变量替换会把当作普通字符。
这说明,当使用双引号包裹变量时,变量中的通配符不会被解析,而是作为字面字符进行匹配。因此,在判断是否包含某个具体字符的时候,例如星号,这种方法是可行的。而如果希望变量中的内容被视为通配符,则不需要使用双引号,但这样又可能带来其他问题,比如变量中的空格或特殊字符导致模式错误。
所以,这种方法在希望精确匹配变量中的内容,而不将其中的通配符视为模式时是可行的,因为双引号包裹确保了变量内容作为文字处理。所以在这个案例中,判断字符串B是否包含字符串A作为子串,无论A中是否包含通配符,都可以正确判断。
例如,当A是"ab"时,如果B中有"ab"这个子串,则会被匹配。而如果B中有"aXYZb",但A中的星号不作为通配符的话,就不会被匹配。这正是我们想要的子串检查,而非模式匹配。
这样,原来的脚本是正确的。
综上所述,最终的脚本应该检查参数的数量是否为2,然后使用双括号的条件判断,在模式匹配中使用双引号包裹变量来确保变量中的字符被视为字面量,从而正确判断是否包含子串。
要编写一个Bash脚本来检查字符串A是否包含在字符串B中,可以按照以下步骤进行:
脚本代码
#!/bin/bash
# 检查是否传入了两个参数
if [[ $# -ne 2 ]]; then
echo "错误:必须提供两个字符串作为参数。"
exit 1
fi
stringA="$1"
stringB="$2"
# 判断字符串B是否包含字符串A
if [[ "$stringB" == *"$stringA"* ]]; then
echo "字符串B包含字符串A。"
else
echo "字符串B不包含字符串A。"
fi
exit 0
脚本解释
参数检查:
if [[ $# -ne 2 ]]:检查是否提供了两个参数。$#表示传入脚本的参数个数,-ne 2表示不等于2。如果参数数量不正确,输出错误信息并退出脚本(
exit 1表示异常退出)。
变量赋值:
stringA="$1":将第一个参数赋值给stringA。stringB="$2":将第二个参数赋值给stringB。
子串判断:
[[ "$stringB" == *"$stringA"* ]]:使用Bash的条件判断和通配符进行模式匹配。==:在双括号中用于字符串比较。*:通配符,匹配任意字符(包括空字符)。*"$stringA"*:表示在stringB中的任意位置存在stringA。
输出结果:
根据条件判断的结果输出相应的信息。
示例用法
./check_substring.sh "hello" "hello world" # 输出:字符串B包含字符串A。
./check_substring.sh "abc" "defghi" # 输出:字符串B不包含字符串A。
注意事项
参数传递:如果字符串包含空格或特殊字符,需要用引号包裹,例如
./check_substring.sh "a b" "c a b d"。空字符串处理:如果
stringA为空字符串(如./check_substring.sh "" "abc"),脚本会认为空字符串是任何字符串的子串,输出“包含”。通配符处理:由于使用双引号包裹变量,
stringA中的通配符(如*)会被当作普通字符处理,而不是模式匹配符。例如,./check_substring.sh "a*" "abc"会输出“不包含”,而./check_substring.sh "a*" "a*"会输出“包含”。
这种方法简洁高效,适用于大多数检查子串的场景。
从服务器端可以看到消耗掉的
token和时间:
slot launch_slot_: id 0 | task 0 | processing task
slot update_slots: id 0 | task 0 | new prompt, n_ctx_slot = 4096, n_keep = 0, n_prompt_tokens = 19
slot update_slots: id 0 | task 0 | kv cache rm [0, end)
slot update_slots: id 0 | task 0 | prompt processing progress, n_past = 19, n_tokens = 19, progress = 1.000000
slot update_slots: id 0 | task 0 | prompt done, n_past = 19, n_tokens = 19
slot release: id 0 | task 0 | stop processing: n_past = 3279, truncated = 0
slot print_timing: id 0 | task 0 |
prompt eval time = 7011.90 ms / 19 tokens ( 369.05 ms per token, 2.71 tokens per second)
eval time = 5139299.67 ms / 3261 tokens ( 1575.99 ms per token, 0.63 tokens per second)
total time = 5146311.57 ms / 3280 tokens
srv update_slots: all slots are idle
srv log_server_r: request: POST /completion 127.0.0.1 200
可以看到推理非常缓慢,速度只有 0.637 token/s ,这个速度甚至还不如我在标准的 Ubuntu Linux 环境下 本地化部署DeepSeek-R1 CPU架构 ( 0.66 token/s )
从观察来看,没有控制参数,负载会随机落到超线程的cpu core,当两个超线程位于同一个cpu core产生竞争,甚至可能不如更少的线程数量计算。
另外,我的 LFS(Linux from scratch) cpupower 没有调整,看起来并没有发挥出CPU最好性能。