树莓派安装NVIDIA P4 GPU运行 nvidia-docker 容器
备注
由于 树莓派 Raspberry Pi OS 安装NVIDIA驱动(归档) 遇到困难挫折,所以我推翻重新采用 Ubuntu Linux for Raspberry Pi作为操作系统,再次尝试安装 nvidia-driver
实践环境
树莓派Raspberry Pi 5 安装了 Respberry Pi OS Ubuntu 24.04.02 LTS ,即 Debian 12 (bookworm),这是一个 ARM 架构的低功耗微型计算机,所以后续安装 安装NVIDIA Linux驱动 需要选择
aarch64架构Nvidia Tesla P4 GPU运算卡 加装了淘宝购买的散热器,并通过
OCuLinkDock连接到 树莓派Raspberry Pi 5
Nvidia Tesla P4 GPU运算卡 加电后再启动连接的 树莓派Raspberry Pi 5 ,进入host主机系统后执行 lspci 命令可以看到识别出 Nvidia Tesla P4 GPU运算卡 :
0001:00:00.0 PCI bridge: Broadcom Inc. and subsidiaries BCM2712 PCIe Bridge (rev 21)
0001:01:00.0 PCI bridge: ASMedia Technology Inc. ASM1182e 2-Port PCIe x1 Gen2 Packet Switch
0001:02:03.0 PCI bridge: ASMedia Technology Inc. ASM1182e 2-Port PCIe x1 Gen2 Packet Switch
0001:02:07.0 PCI bridge: ASMedia Technology Inc. ASM1182e 2-Port PCIe x1 Gen2 Packet Switch
0001:03:00.0 3D controller: NVIDIA Corporation GP104GL [Tesla P4] (rev a1)
0002:00:00.0 PCI bridge: Broadcom Inc. and subsidiaries BCM2712 PCIe Bridge (rev 21)
0002:01:00.0 Ethernet controller: Raspberry Pi Ltd RP1 PCIe 2.0 South Bridge
架构
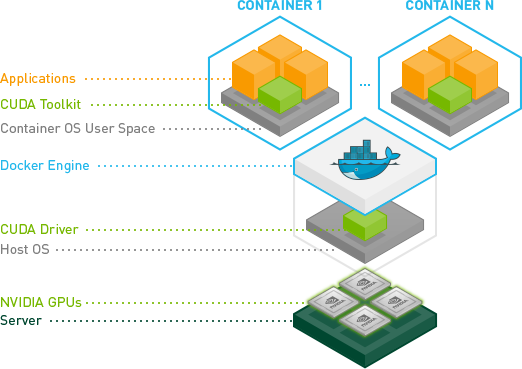
CUDA软件堆栈
NVIDIA将GPU驱动和开发组件(Toolkits)分别组合成:
cudacuda-drivers:cuda的子集
由于虚拟化和容器化技术的发展,我们可以在不同的层次分别安装:
物理主机:
cuda-drivers虚拟机(PassThrough GPU):
直接在虚拟机内运行应用及开发:
cuda虚拟机内通过容器运行应用及开发:
虚拟机:
cuda-drivers容器:
cuda
(裸金属)容器:
cuda
简而言之:
只有实际运行应用及开发的
主机/虚拟化/容器层才需要完整安装cuda其他作为支持层的层只需要安装
cuda-dirvers
Host主机安装 nvidia-driver
如上文所述,在 树莓派Raspberry Pi 5 Host主机上我规划部署 Docker (作为 Kubernetes 主机节点),所以只需要安装 cuda-drivers
备注
在 安装NVIDIA Linux驱动 我曾经采用过两种方式安装 cuda-drivers :
手工下载安装 NVIDIA官方提供的 P40 驱动 (我在 树莓派 Raspberry Pi OS 安装NVIDIA驱动(归档) 也尝试了手工安装驱动方法,但是在Raspberry Pi OS上没有成功
通过Linux发行版软件仓库方式安装NVDIA CUDA驱动
本次实践我采用后者 软件仓库方式
准备工作
按照 安装CUDA准备 检查和准备:
由于 树莓派Raspberry Pi 5 只有8GB内存,所以不建议启用 Above 4G Decoding BIOS设置 (应该也没有这个BIOS设置选项)
验证系统已经安装gcc以及对应版本:
gcc --version
NVIDIA驱动需要主机已经安装了 Kernel headers 和 开发软件包
如果系统尚未安装 gcc 可以采用 Debian精简系统初始化 纯后台服务器系统安装开发工具的方式(安装 build-essential 为主):
sudo apt install build-essential cmake vim-nox python3-dev -y
CUDA驱动需要内核头文件以及开发工具包来完成内核相关的驱动安装,因为内核驱动需要根据内核进行编译
安装 linux-headers :
apt-get install linux-headers-$(uname -r)
CUDA软件仓库
从NVIDIA官方提供 NVIDIA CUDA Toolkit repo 下载
由于是 树莓派Raspberry Pi 5 ARM架构,我选择了
Linux >> arm64-sbsa (Server Base System Architecture) >> Native >> Ubuntu >> 22.04 >> deb (network)Compilation 步骤可选
Native(只编译相同架构的代码)和Cross(可编译不同架构代码),我选择NativeUbuntu版本选择
22.04对应的是 Debian 12 (bookworm),如果选 Ubuntu 24.04 则对应的是debian 13
安装步骤:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/sbsa/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
仓库安装 cuda-drivers
备注
使用软件仓库网络安装 cuda-drivers 需要主机安装好对应的 linux-headers
sudo apt-get -y install cuda-drivers
安装过程会使用 动态内核模块支持(DKMS) 编译NVIDIA内核模块,果然在NVIDIA官方支持的Ubuntu平台编译安装非常顺利,没有遇到 树莓派 Raspberry Pi OS 安装NVIDIA驱动(归档) 中痛苦的折磨。
然而...
GPU初始化异常排查
虽然驱动安装正常,重启系统后却发现 nvidia-smi 执行显示驱动没有加载。WHY
检查
dmesg -T输出,发现原因是总线没有响应初始化命令导致驱动加载失败:
[ 8.544704] nvidia: loading out-of-tree module taints kernel.
[ 8.544719] nvidia: module license 'NVIDIA' taints kernel.
[ 8.544721] Disabling lock debugging due to kernel taint
[ 8.544726] nvidia: module license taints kernel.
[ 8.599767] nvidia-nvlink: Nvlink Core is being initialized, major device number 508
[ 8.611680] nvidia 0000:03:00.0: enabling device (0000 -> 0002)
[ 8.613215] NVRM: The NVIDIA GPU 0000:03:00.0
NVRM: (PCI ID: 10de:1bb3) installed in this system has
NVRM: fallen off the bus and is not responding to commands.
[ 8.613228] nvidia: probe of 0000:03:00.0 failed with error -1
[ 8.613261] NVRM: The NVIDIA probe routine failed for 1 device(s).
[ 8.613263] NVRM: None of the NVIDIA devices were initialized.
[ 8.613946] nvidia-nvlink: Unregistered Nvlink Core, major device number 508
[ 9.118573] nvidia-nvlink: Nvlink Core is being initialized, major device number 508
[ 9.118591] NVRM: The NVIDIA GPU 0000:03:00.0
NVRM: (PCI ID: 10de:1bb3) installed in this system has
NVRM: fallen off the bus and is not responding to commands.
[ 9.146074] nvidia: probe of 0000:03:00.0 failed with error -1
[ 9.146126] NVRM: The NVIDIA probe routine failed for 1 device(s).
[ 9.146129] NVRM: None of the NVIDIA devices were initialized.
[ 9.146997] nvidia-nvlink: Unregistered Nvlink Core, major device number 508
备注
目前初步判断可能存在问题:
使用 OCuLink 连接存在硬件问题或使用问题
购买的 Nvidia Tesla P4 GPU运算卡 可能有硬件隐患
我准备采用替换方法排查,后续来尝试解决这个问题
Host主机安装NVIDIA Container Toolkit
配置软件生产级仓库:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
另外一种仓库是实验性仓库,通过修订 /etc/apt/sources.list.d/nvidia-container-toolkit.list 配置(我没有使用):
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
更新仓库的软件包列表:
sudo apt-get update
安装 NVIDIA Container Toolkit:
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
配置
备注
确保已经完成以下软件包:
受支持的容器引擎(Docker, Containerd, CRI-O, Podman)
已安装 NVIDIA Container Toolkit
配置Docker
使用
nvidia-ctk命令配置容器运行时:
nvidia-ctk 命令配置容器运行时sudo nvidia-ctk runtime configure --runtime=docker
nvidia-ctk 会修订 /etc/docker/daemon.json ,这样Docker就会使用 NVIDIA Container Runtime
重启 Docker 服务:
sudo systemctl restart docker
配置containerd(为kubernetes)
对于使用 containerd 的Kubernetes环境,使用以下命令配置运行时:
sudo nvidia-ctk runtime configure --runtime=containerd
此时 nvidia-ctk 命令会修订 /etc/containerd/config.toml 配置
参考
Using NVIDIA GPU within Docker Containers (在安装
NVIDIA Container Toolkit之前,先参考 CUDA Installation Guide for Linux 完成cuda-driver安装)Installing the NVIDIA Container Toolkit 从2023年8月开始,
nvidia-docker已经被NVIDIA Container Toolkit替代,所以本文实践部署替代了之前的 Docker运行NVIDIA容器JeffGeerling的网站上 Raspberry Pi PCIe Database#GPUs (Graphics Cards)